RAG
RAG Pipelines
Advanced
This guide brings everything together into
complete RAG Pipelines
— from simple query-answer flows to sophisticated agentic, multi-step, and stateful RAG systems using LangGraph. You will learn end-to-end architectures, query transformation, context management, streaming, evaluation, hallucination controls, and production-ready patterns with full working code.
RAG Pipelines
What Is a RAG Pipeline?
A RAG Pipeline is an orchestrated sequence of steps that turns a user query into a grounded, accurate response by retrieving relevant context and feeding it to an LLM. In LangGraph, this becomes a
stateful, controllable, debuggable graph
instead of fragile prompt chains.
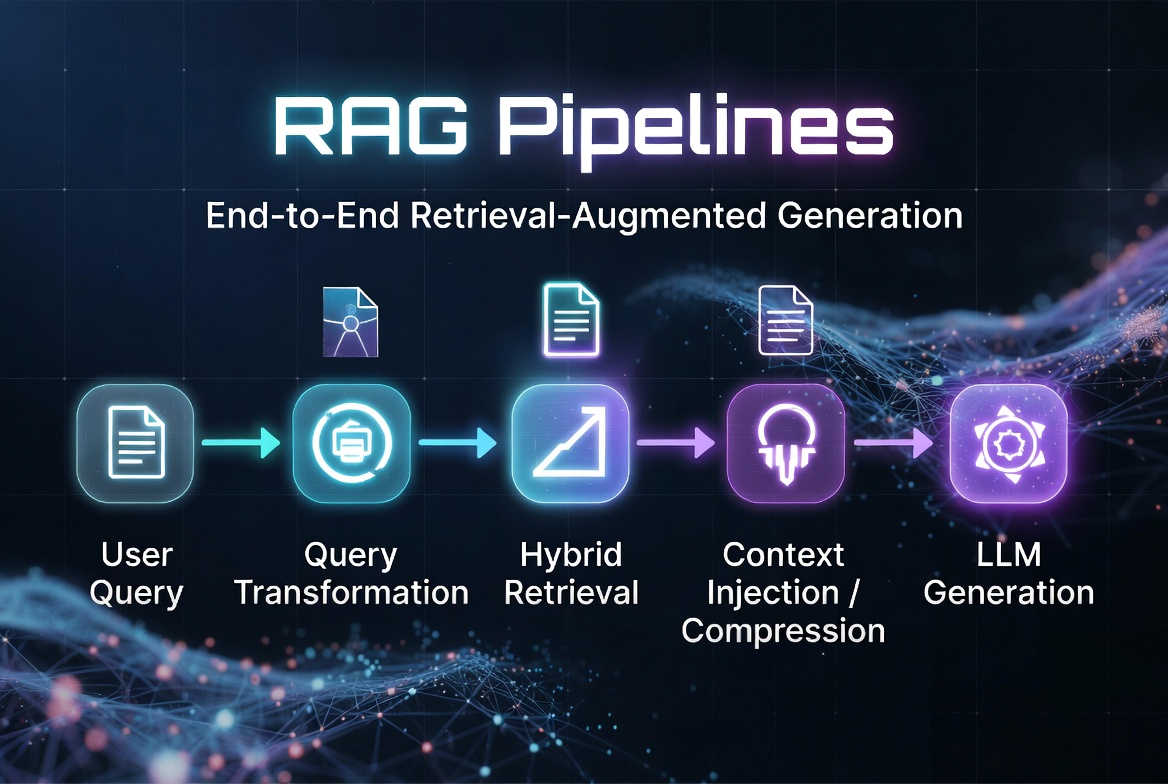
End-to-End Retrieval Workflows
Basic structure:
- Query → Transformation
- Retrieval (possibly multi-step)
- Context Post-processing / Compression
- Generation
- (Optional) Self-correction / Verification
Query Transformation
Improve retrieval quality before searching.
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
query_rewriter = ChatPromptTemplate.from_template(
"Rewrite the following question to be more specific and effective for vector search.\n"
"Original: {question}\nRewritten:"
)
def transform_query(state):
question = state["messages"][-1].content
rewritten = llm.invoke(query_rewriter.format(question=question))
return {"messages": [rewritten], "original_question": question}Retrieval Pipelines
from typing import TypedDict, Annotated, List
from langchain_core.documents import Document
import operator
class RAGState(TypedDict):
messages: Annotated[list, operator.add]
context: List[Document]
original_question: str
def retrieve(state: RAGState):
query = state.get("original_question") or state["messages"][-1].content
docs = retriever.invoke(query) # ensemble or advanced retriever
return {"context": docs}Context Injection Pipelines
def inject_context(state: RAGState):
context_text = "\n\n".join([
f"Source: {doc.metadata.get('source', 'unknown')}\n{doc.page_content}"
for doc in state["context"]
])
prompt = f"""You are a helpful assistant. Use only the provided context to answer.
Context:
{context_text}
Question: {state["messages"][-1].content}
Answer:"""
return {"prompt": prompt}Multi-Step RAG Workflows
def grade_documents(state: RAGState):
relevant = []
for doc in state["context"]:
# Use LLM to grade relevance
score = llm.invoke(f"Is this relevant to '{state['messages'][-1].content}'? YES/NO only.\n{doc.page_content[:400]}")
if "YES" in score.content.upper():
relevant.append(doc)
return {"context": relevant}
# Graph with conditional routing
graph.add_node("retrieve", retrieve)
graph.add_node("grade", grade_documents)
graph.add_node("generate", generate)
graph.add_edge(START, "retrieve")
graph.add_edge("retrieve", "grade")
graph.add_conditional_edges(
"grade",
lambda s: "generate" if len(s["context"]) > 0 else "rewrite_query",
{"generate": "generate", "rewrite_query": "transform_query"}
)Agentic RAG Pipelines
Use tools + ReAct style.
from langgraph.prebuilt import create_react_agent
from langchain.tools import tool
@tool
def retrieve_knowledge(query: str) -> str:
"""Retrieve relevant documents for the query."""
docs = retriever.invoke(query)
return "\n\n".join([doc.page_content for doc in docs[:5]])
agent = create_react_agent(
model=ChatOpenAI(model="gpt-4o"),
tools=[retrieve_knowledge],
checkpointer=MemorySaver()
)
# Run with memory
result = agent.invoke({
"messages": [("user", "Compare LangGraph and CrewAI in 2026")]
}, config={"configurable": {"thread_id": "rag_agent_42"}})ReAct + RAG Systems
Combine reasoning with retrieval in a loop.
from langgraph.graph import StateGraph, END
def should_retrieve(state):
# LLM decides if more retrieval is needed
decision = llm.invoke("Do I need more information? YES/NO")
return "retrieve" if "YES" in decision.content.upper() else "generate"Multi-Agent RAG Architectures
- Router Agent → decides which retriever / knowledge base to use
- Critic Agent → grades answer quality
- Research Agent → performs multi-hop retrieval
- Summarizer Agent → final synthesis
Streaming RAG Pipelines
async for event in app.astream_events({"messages": [HumanMessage(content=query)]}, version="v2"):
if event["event"] == "on_chat_model_stream":
print(event["data"]["chunk"].content, end="")Stateful RAG Workflows (LangGraph Advantage)
Use MemorySaver or PostgresSaver for:
- Conversation memory
- Retrieved context persistence
- Human-in-the-loop corrections
- Multi-turn research sessions
RAG Evaluation Strategies
from ragas import evaluate
from ragas.metrics import (
faithfulness, answer_relevancy, context_precision, context_recall
)
dataset = ... # your test questions + ground truth
results = evaluate(dataset, metrics=[faithfulness, answer_relevancy, context_precision])
print(results)
Track: Faithfulness, Answer Relevancy, Context Precision/Recall, Latency, Cost.
Hallucination Reduction Techniques
- Strict context-only prompting
- Document grading + filtering
- Self-reflection / self-critique
- Citation enforcement
- Post-generation verification with another LLM
- Knowledge cutoff awareness
def verify_answer(state):
verification_prompt = f"""Does the answer contain information not present in the context?
Context: {state['context']}
Answer: {state['messages'][-1].content}
Reply ONLY with VERIFIED or HALLUCINATED."""
result = llm.invoke(verification_prompt)
if "HALLUCINATED" in result.content:
return "rewrite"
return ENDCommon RAG Pipeline Mistakes
- Single naive retrieval step for complex queries
- No query transformation or routing
- Feeding raw noisy context to LLM
- No hallucination / relevance checks
- Ignoring state management across turns
- No evaluation or monitoring
- Fixed k without dynamic adjustment
- Poor error handling and fallback strategies
Best Practices for RAG Pipelines
- Start simple, then add agentic/multi-step capabilities
- Always include query rewriting and document grading
- Use hybrid/ensemble retrievers
- Implement streaming + stateful graphs with LangGraph
- Add self-correction loops
- Enforce citations and source transparency
- Continuously evaluate with real user queries
- Monitor latency, token usage, and relevance scores
- Design for human-in-the-loop intervention
- Abstract pipeline components for easy experimentation
Pro Tip – Full Production RAG Pipeline in LangGraph
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.postgres import PostgresSaver
workflow = StateGraph(RAGState)
workflow.add_node("transform_query", transform_query)
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade", grade_documents)
workflow.add_node("generate", generate)
workflow.add_node("verify", verify_answer)
workflow.add_edge(START, "transform_query")
workflow.add_edge("transform_query", "retrieve")
workflow.add_edge("retrieve", "grade")
workflow.add_edge("grade", "generate")
workflow.add_edge("generate", "verify")
workflow.add_conditional_edges("verify", lambda s: END if "VERIFIED" in ... else "generate")
app = workflow.compile(checkpointer=PostgresSaver.from_conn_string(...))
RAG Pipelines powered by LangGraph turn fragile prompt chains into robust, observable, and evolvable AI systems.
AI agent LangGraph Python RAG